この例では、メタデータがどのように CSV のデータ形式に対応するかを説明します。
CSV データのページ アイテムの順序はメタデータの pages ディメンションの順序と一致します。
CSV データのヘッダーのメタデータを提供する二つのエンドポイントは以下のとおりです。
- ビューのディメンションのメタデータの取得
(/models/{modelId}/views/{viewId}): ページ セレクター、行、列のディメンションを提供 - ディメンションのアイテムで選択したデータの取得 (
/models/{modelId}/views/{viewId}/dimensions/{dimensionId}/items): 列ヘッダーのアイテムを提供
これらのエンドポイントを使えば、データ全体をダウンロードせずに CSV データの構造を把握することができます。
以下の例は、ビューのディメンションのメタデータの取得 (/models/{modelId}/views/{viewId}) エンドポイントの出力と CSV データとの対応関係を示しています。
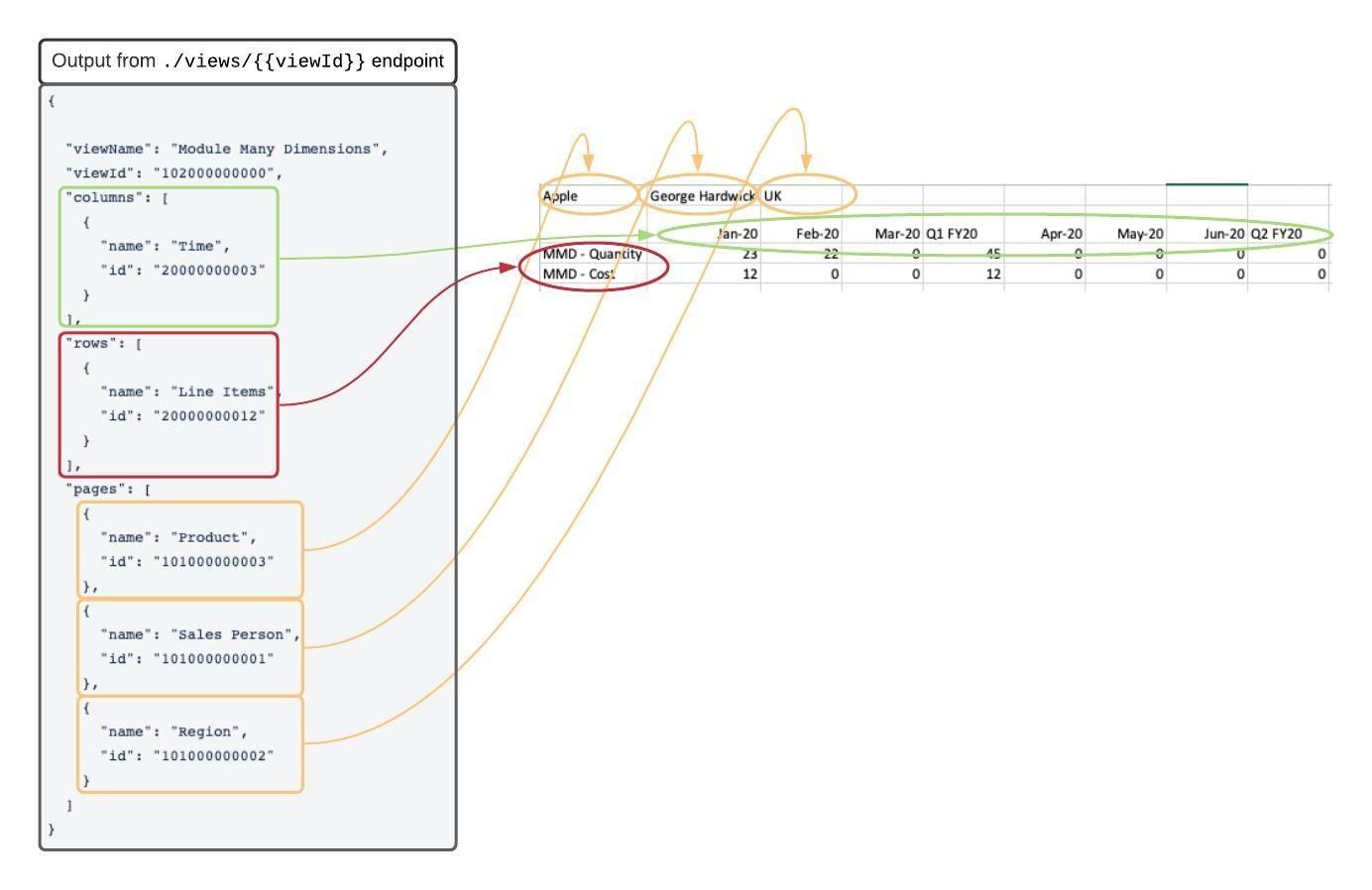
メタデータの ID を dimensionId として使用してディメンションのアイテムのリストを検索できます。ディメンションの選択済みアイテムの取得 (/views/{viewId}/dimensions/{dimensionId}/items) エンドポイントを使ってこのクエリを実行します。
たとえば、Time の ID を使用する場合、ディメンションの選択済みアイテムの取得 (/views/{viewId}/dimensions/20000000003/items) エンドポイントは列ヘッダーのアイテムを返します。

アイテムの順序は CSV ファイルの列の順序と一致します。ビューに適用するフィルターがすべて API コールに適用されます。アイテムは CSV ファイルに表示される列とまったく同じものになります。

