This example shows how the metadata maps to the CSV data format.
The order of the pages items in the CSV data matches the order of the pages dimensions in the metadata.
The two endpoints that provide the metadata for the headers of the CSV data are:
- Retrieve metadata for dimensions on a view
(/models/{modelId}/views/{viewId})- provides the page selector, row, and column dimensions - Retrieve selected data for items in a dimension (
/models/{modelId}/views/{viewId}/dimensions/{dimensionId}/items) - provides the items in the column headers
You can use these endpoints to understand the structure of the CSV data without the need to download the complete data.
The following example shows the output of the Retrieve metadata for dimensions on a view (/models/{modelId}/views/{viewId}) endpoint and how it maps to the CSV data.
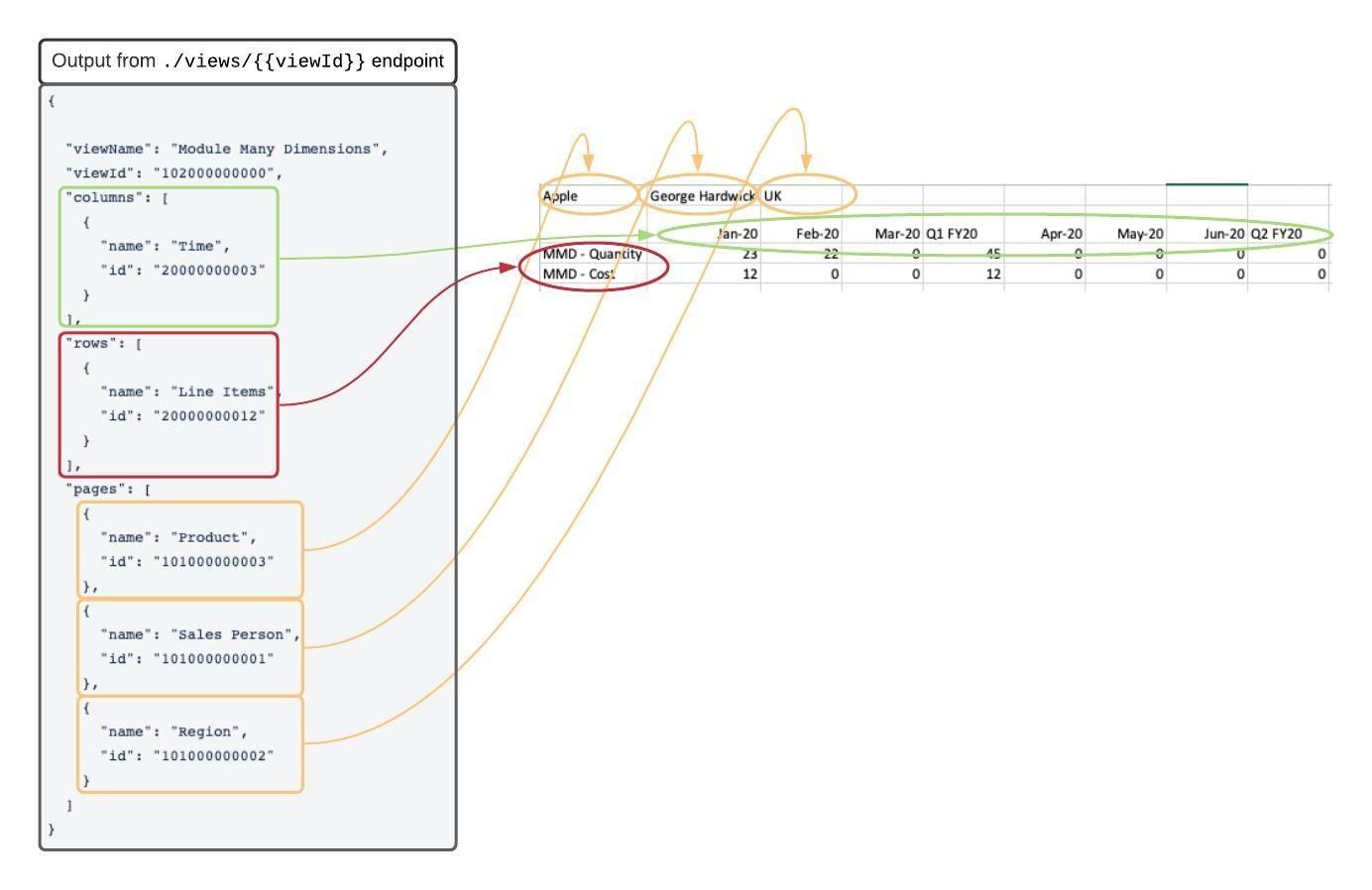
You can use IDs provided in the metadata as the dimensionId to look up the list of items of the dimension. Use the Retrieve selected items in a dimension (/views/{viewId}/dimensions/{dimensionId}/items) endpoint to perform this query.
For example, if you use the ID for Time, the Retrieve selected items in a dimension ( /views/{viewId}/dimensions/20000000003/items) endpoint returns the items in the column headers.

The order of the items matches the order of the columns in the CSV file. Any filters that apply in the view apply to the API call. The items are exactly as the columns appear in the CSV file.

