大規模な組織では、社内のプロセスとセキュリティの要求、及び規制機関の要件を満たすために、職務の分離が必要になることがよくあります。
これらの要件に対応するために、データへのアクセス (特にライブの本番データ) は知る必要がある人にしか知らせない形で常に保護する必要があります。
職務の分離の度合いは各組織で決定されます。その決定は、リソースの調達やサイトの複雑さなど、さまざまな要因に左右されます。Anaplan では、以下を使用して、組織で定義された職務の分離をサポートできます。
- ワークスペース
- データ フロー
- モデル ロール
- 選択的アクセス
職務の分離の例
この例では、アプリケーション ライフサイクル管理 (ALM) プロセスで職務の分離を使用する方法を示しています。
その目的は、職務の分離の背景にあるコンセプト、及びそれをサポートする環境を設計、構築する際の考慮事項を説明することです。こうしたコンセプトは地理的に分散した場所向けのワークスペースや、営業とマーケティングといった機能領域の分離など、他のシナリオに簡単に応用できます。
ワークスペース
ALM では最初にワークスペース レベルで職務の分離を行います。堅牢なデザインによって、本番と非本番の業務をそれぞれ別のワークスペースに配置して業務を分離します。ALM では次に、必要なワークスペースでのみデータ (特にライブ本番データ) が利用できるようにワークスペース間のデータ フローをデザインする必要があります。
アプリケーション ライフサイクル管理の基本的な導入には、 開発、テスト、本番という三つのワークスペースが含まれます。
データ フロー
データ フローのデザインでは、開発ワークスペースとテスト ワークスペースにライブ本番データが置かれないようにする必要があります。職務の分離の計画には、開発ワークスペースとテスト ワークスペースで使用されるライブ データをサニタイズ及び匿名化するプロセスが含まれる場合があります。
ライブの本番ワークスペースに展開する際、モデルの同期を使って開発ワークスペースから本番ワークスペースに構造情報だけがコピーされます。
本番ワークスペースのライブ データは、Anaplan データ ハブか外部のサードパーティ ソースからインポートできます。以下の表は、この例の各ワークスペースへのデータ入力を示したものです。
| ワークスペース 1 のデータ入力:開発 | ワークスペース 2 のデータ入力:テスト | ワークスペース 3 のデータ入力:本番 |
| ダミー データ (.txt ファイル) | サニタイズされたテスト データ | ライブ データのモデル間インポート |
| インポートによる、テストからのサニタイズされたテスト データ | 開発からのモデル同期 | サードパーティ ソースからモデルへのインポート |
| 開発からのモデル同期 |
ワークスペース管理者は、ソース モデルを使って本番データのインポート ソースを再マッピングできます。たとえば、テスト ワークスペースのモデルが開発ワークスペースのサニタイズされたデータ モデルからデータを取得するとします。
開発ワークスペースのモデルが本番ワークスペースのモデルと同期される場合、本番ワークスペースの管理者は、開発ソースではなく本番ソースに本番データのインポート ソースを再マッピングする必要があります。これを行うには、ワークスペース管理者に開発と本番両方のワークスペースへのアクセス権が必要になります。
モデル ロール
ユーザー グループの実際の活動を反映した、意味のあるモデル ロールを作成します。一部のモデル ロールに他のロールよりも高いレベルのアクセスを許可することで、知る必要がある人にしか知らせない形でデータを保護できます。
開発ワークスペースと本番ワークスペースでモデル ロールを同じにする必要はありません。さまざまなユーザー タイプが実行するであろうアクティビティを考慮し、それに応じてロールを設計します。こうすることで、職務の分離の導入がはるかに容易になります。
選択的アクセス
選択的アクセスを使ってデータへのアクセスを制御することもできます。選択的アクセスは、読み取り及び書き込み権限を使用して、リスト レベルで適用されます。デフォルトはアクセスなしです。リストがアクセスなしに設定されている場合、管理者がどのロールにアクセス権を付与するかを指定するまでリストにアクセスできません。
まとめ
ワークスペースとそれに付随するモデルへのアクセスは、各ユーザーに割り当てられるモデル ロールによって制限されます。リストに選択的アクセスを適用することで、よりきめ細かいレベルでアクセスを制限できます。すべてのアクセス権で、ワークスペースで実施されるプロセスをサポートする必要があります。たとえば以下のようなケースが考えられます。
- 同期後にインポートを再マッピングするために、本番ワークスペースの管理者がテスト ワークスペースへのアクセス権を必要としている。
- サニタイズされたデータをインポートするために、テストの管理者が開発へのアクセス権を必要としている。
- モデルの構造情報を構成する非本番リストに本番の管理者が選択的アクセスを適用する。
- 選択的アクセスを使って、構造情報を構成するリストにユーザーがアクセスできないようにすることができます。
以下の表は、職務の分離の概要を表したものです。
| ワークスペース 1 開発 | ワークスペース 2 テスト | ワークスペース 3 本番 | |
| モデル ロール別のアクセス権 | Anaplan コンサルタント | 社内の IT 部門 | 社内の IT 部門 |
| 社内の IT 部門 | ワークスペース 2/3 の管理者 | ワークスペース 2/3 の管理者 | |
| ワークスペース 1/2 の管理者 | テスター (適切なロール) | エンド ユーザー | |
| モデル ビルダー | |||
| 適用される選択的アクセス | 構造情報 | 構造情報 | 構造情報 |
この表から以下のことがわかります。
- アクセスするロールの数が最も多いのが開発ワークスペースです。ここでは既存モデルへの変更と新しいモデルの構築を行います。このワークスペースのデータはサニタイズされていて商業的価値もありませんが、モデルの構造情報には意味があり、アクセスを制限することで保護する必要があります。
- テスト ワークスペースにはワークスペース管理者とテスターしかアクセスできません。モデルのワークスペースと適切なロールにアクセスできるユーザーによってテストが実施されます (開発ワークスペースのモデル ビルダーや本番ワークスペースのビジネス ユーザーなど)。このワークスペースのデータもサニタイズされており、モデルの構造情報を保護する必要があります。テスト モデルが展開モードになっていることを確認します。
- より多くの数のユーザーがライブ本番データにアクセスしますが、そのアクセスはモデル内で割り当てられたロールに制限されます。社内 IT リソースもメンテナンスのためにワークスペースにアクセスする必要がある場合がありますが、ワークスペースのモデルへのアクセス権は付与しないようにします。
- インポート ソースの再マッピングを行うには、ワークスペース管理者に一つ以上のワークスペースへのアクセス権が必要です。
モデル ロールとデータ
この図は、ユーザー アーキテクチャ、及びワークスペースの同期とデータ インポートを示したものです。テスト ワークスペースと開発ワークスペースでは本番データに一切アクセスできません。モデル ロールによって、サイトでの職務の分離が確保されます。
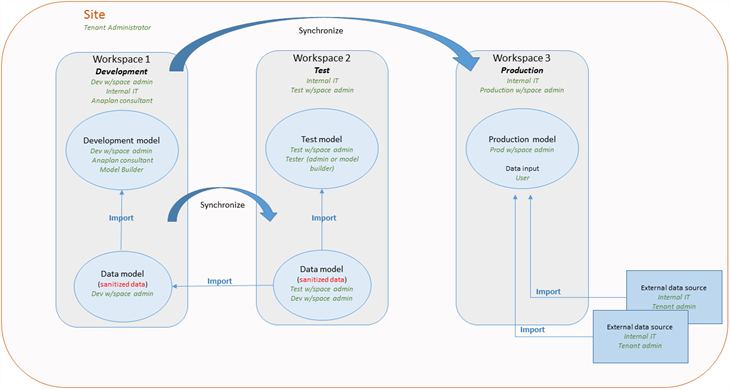
データ ハブが展開されている環境では、データの流れが以下のようになります。
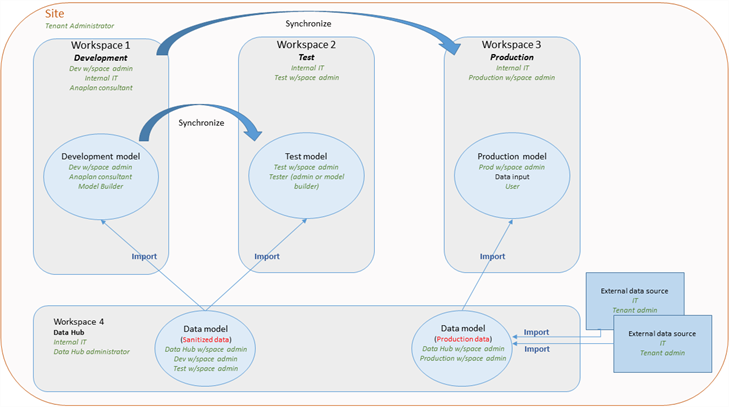
ご覧のとおり、他のワークスペースのユーザーは本番データに依然としてアクセスできません。

