プロセスを構成して、アクションのインポート、エクスポート、又は削除を組み合わせて 1 回で実行します。
Optimizer サービスをプロセスに含めることはできません。
選択的アクセスが有効になっているモデル リストから統合をエクスポートする場合:
- ワークスペース管理者がリストに社内 (フル アクセス) を付与していることを確認してください。
- 社内 (フル アクセス) は統合サービスを表す選択的アクセスの一種です。
プロセスを構成するには以下を実行します。
![新しい統合と [Process] ドロップダウン メニュー。](https://assets-us-01.kc-usercontent.com:443/cddce937-cf5a-003a-bfad-78b8fc29ea3f/952279e5-91d2-4043-8417-22e74ff744f1/new-integra-drop-down.png)
- 左側のメニューから [Integrations & Processes] を選択します。
- 右側にある [New integration / process] を選択します。
- ドロップダウンから [Process] を選択します。
- ダイアログの各項目に入力します。
- [Name] に名前を入力し、[Workspace]、[Model]、[Action] の各ドロップダウン メニューからワークスペース、モデル、アクションを選択します。
先頭と末尾が文字か数字の一意の名前を 60 文字以内で入力します。使用できる文字は ラテン アルファベット のみです。スペース、ハイフン (-)、アンダースコア (_) 以外の特殊文字は使用できません。
- [Name] に名前を入力し、[Workspace]、[Model]、[Action] の各ドロップダウン メニューからワークスペース、モデル、アクションを選択します。
- [Connection] 列で、プロセス アクションごとに接続を選択します。
- プロセス アクションごとにデータ ソース (インポートごと) かターゲット (エクスポートごと) を選択します。
- 前のエクスポートのダウンロード ファイルを上書きするには、行の右側にある ファイルを上書き チェックボックスをオンにします。
注記:プロセスにモデル間インポートしか含まれていない場合、[Conection] 列と [Data source or target] 列は空白として表示されます。これは、必要なクラウド接続、ソース、ターゲットがないためです。
- 前のエクスポートのダウンロード ファイルを上書きするには、行の右側にある ファイルを上書き チェックボックスをオンにします。
- [Create] を選択し、新しいプロセスの設定を受け入れて適用します。
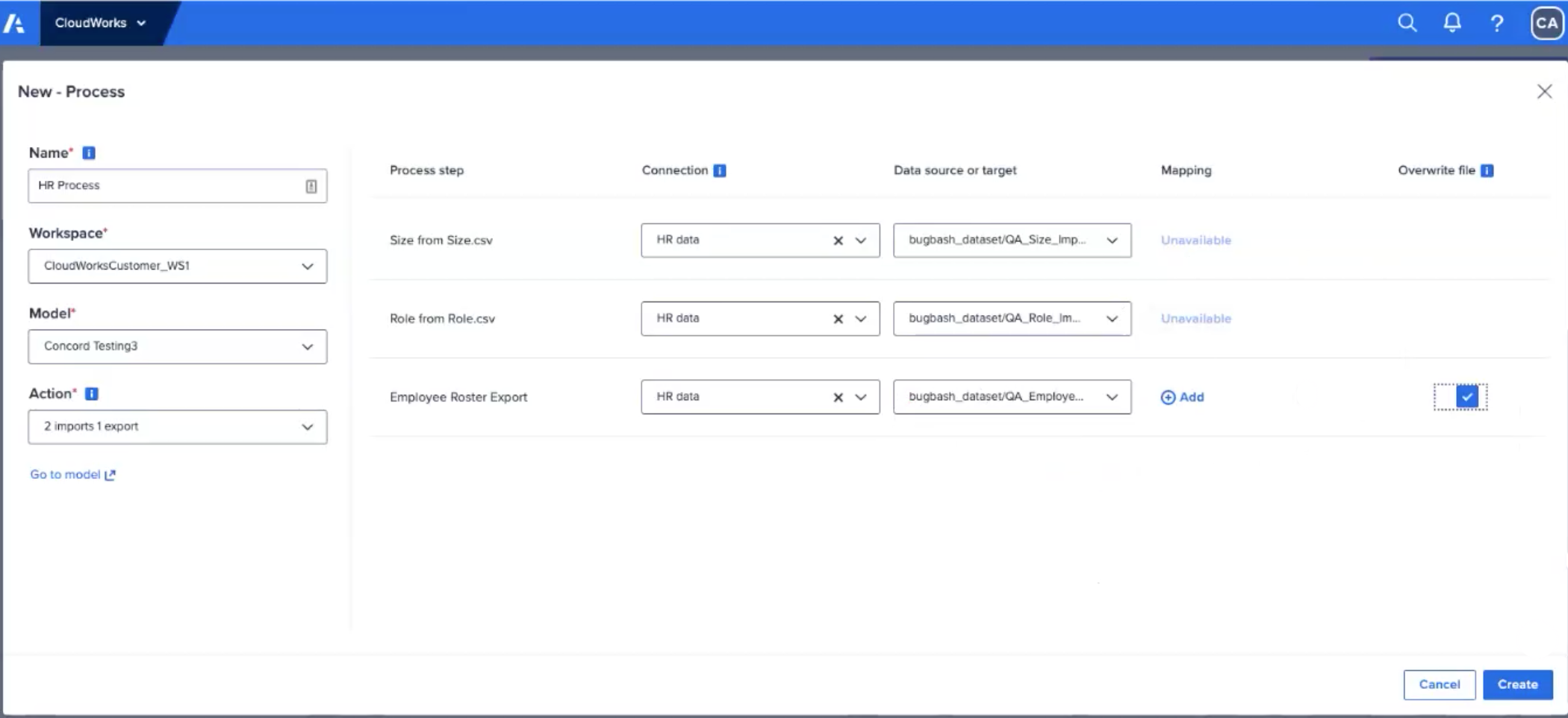
Google BigQuery (GBQ) を使用してプロセスをクラウド ソースとして構成しており、プロセスにエクスポートが含まれている場合は以下を実行します。
- データ型を一致させる必要があります。
- Anaplan と BigQuery のフィールドをマッピングします (Google BigQuery との統合に関するこちらのページを参照)。
- [Add] を選択してマッピング プロセスを開始します。
- 右側にある を選択し、現在のデータを削除して新しいデータをアップロードします。
- [Mapping] ダイアログが表示されます。
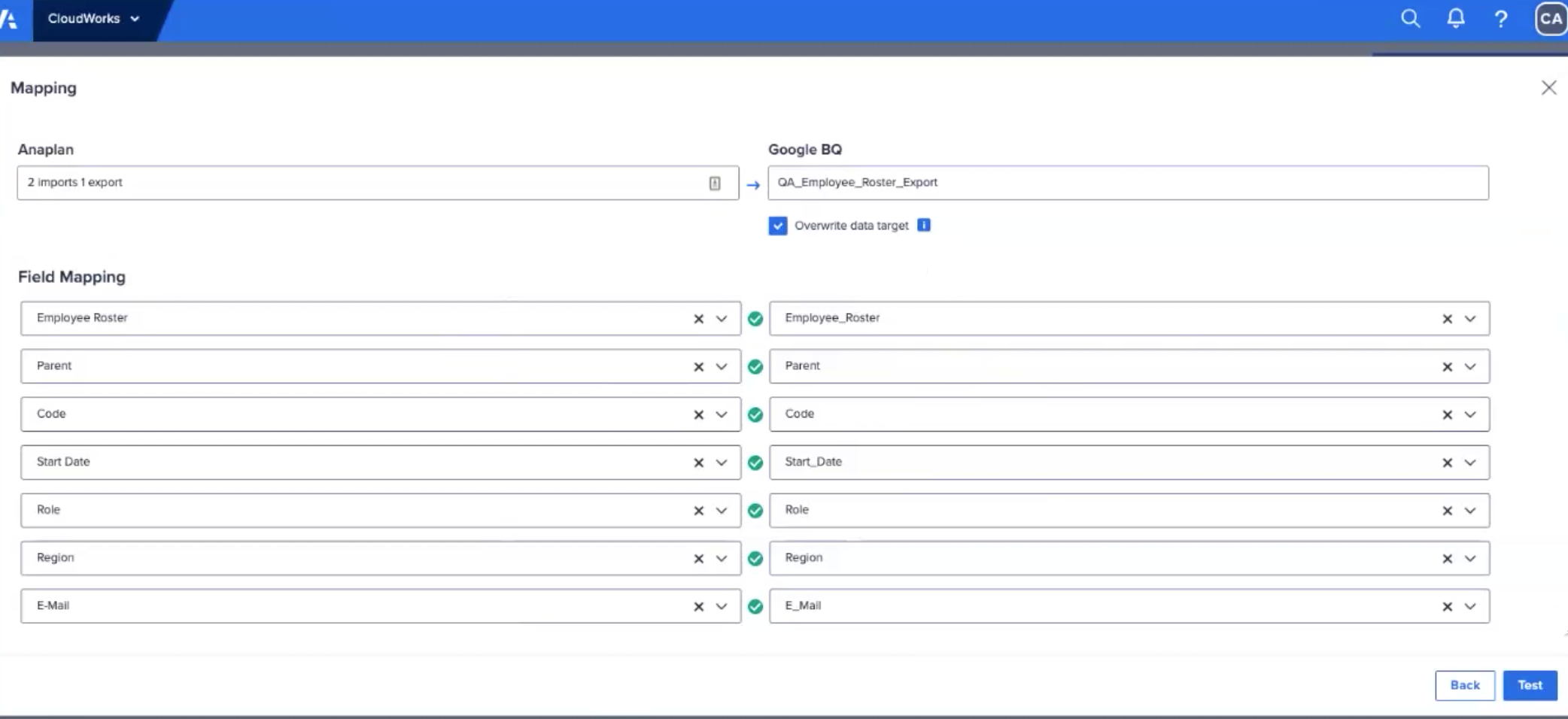
フィールドが正しくマッピングされている場合、 Anaplan と BigQuery の列の間に緑のチェックマークが表示されます。
- マッピングされたフィールドを検証するには [Test] を選択します。又は、ドロップダウンを使用してフィールドをマッピングします。
- [Create] を選択します。完了すると、次の画面の右側に [Mapped] が表示されます。
次のメッセージが表示されます。プロセス統合を保存しました

